玩过类似魔兽世界这种网游的朋友,应该都有组团刷副本的经历。然而有些时候我们会发现,虽然加了很多游戏好友,但自己想刷副本时经常会缺“奶”,缺“T”。能不能根据玩家在线的时间段偏好推荐相似的好友呢?
思考
推荐的本质是排序。给用户推荐用户,就是要找到一个相似度评估函数来衡量两个用户的在线时间段是否相似。然后把目标玩家与所有玩家的相似度一一计算,并按序推荐。
在介绍我的做法前,列三个遇到的问题:
- 如何表示每个玩家的在线习惯,新玩家怎么办?
- 如何设计相似度评估函数?
- 系统如何支持千万以上量级的玩家?
如果是你,如何解决上面的问题。
我的做法
在线向量
使用一个24维向量描述用户24个小时的在线习惯,每一维表示玩家在此时刻内在线的期望,称为在线向量。
如下图,假设我们有一个玩家A,他某天在12:00到13:00之间上线了一会,晚上在20点过也上线了一会。

我们如果粗略的认为A在12:00-13:00,20:00-21:00之间和的在线概率为1,就得到了下图中的在线向量。

如果从长期来看,将一段时间内每天的时间向量取平均值,就得到了这段时间的平均向量。下图中的绿色方框是玩家A经过四天的观察得到的在线向量,即
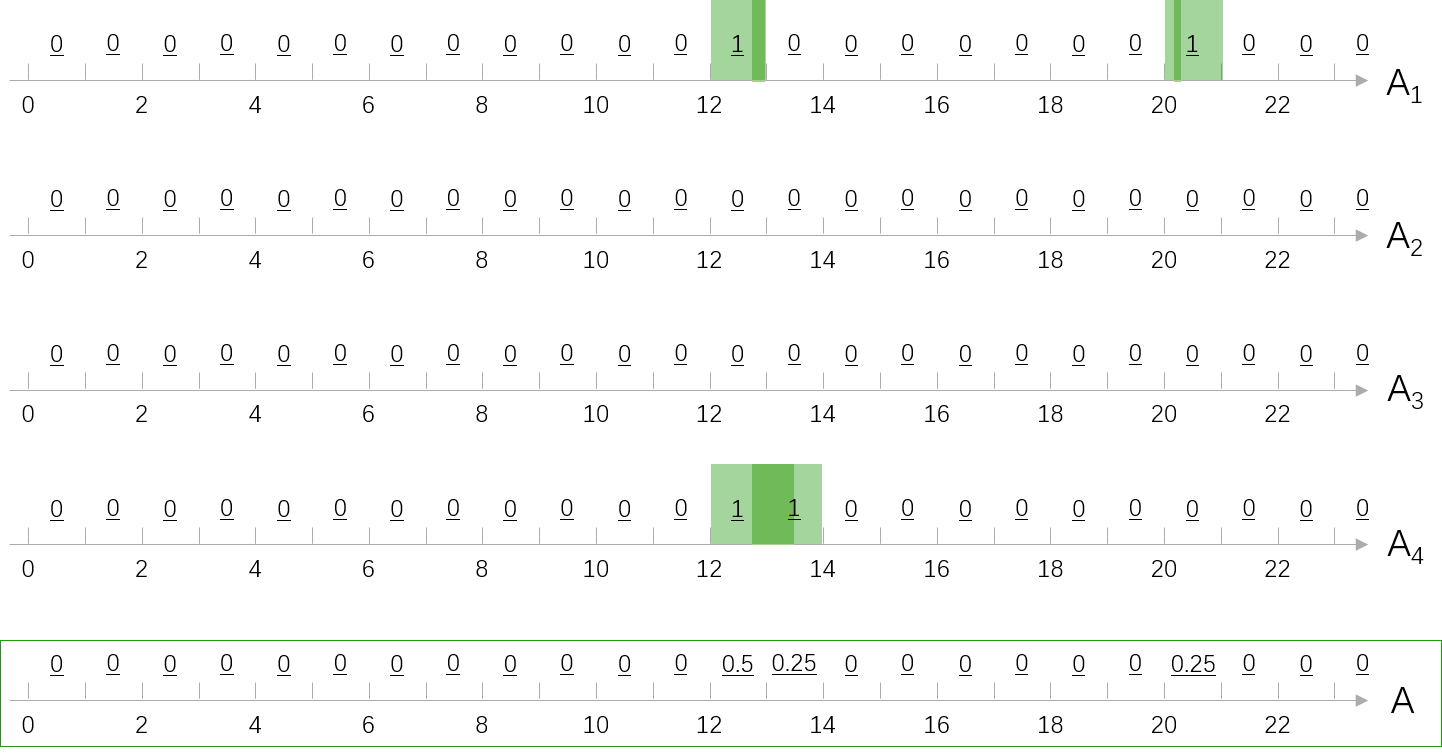
$$ V_A = (0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.5, 0.25, 0, 0, 0, 0, 0, 0, 0.25, 0, 0, 0) $$
使用在线向量,我们可以粗略刻画玩家在某个时间点在线的期望。此外,在线向量的norm也在一定程度上刻画了用户的活跃情况,对于频繁上线的用户,其在线向量的norm会大于不常上线的用户。我们可以利用这点,尽量给推荐更加活跃的用户作为好友。
在线相似度
对于两个用户之间的在线相似度,我们使用两人的在线向量的內积表示。这个內积可以理解为两个玩家在一天中“相遇”的期望。
$$ S_{AB} = V_A \cdot V_B $$
假设我们有3个用户,
$$ \begin{aligned} V_A & = (0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.5, 0.25, 0, 0, 0, 0, 0, 0, 0.25, 0, 0, 0) \\ V_B & = (1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.1, 0, 1, 0) \\ V_C & = (1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0.5, 0, 0, 0, 0, 0, 0, 0.5, 0, 0, 0) \end{aligned} $$
假设我们要给A推荐用户,分别计算A与B、A与C的相似度,
$$ \begin{aligned} S_{AB} & = V_A \cdot V_B = 0.25 \times 0.1 = 0.025 \\ S_{AC} & = V_A \cdot V_C = 0.5 \times 1 + 0.25 \times 0.5 + 0.25 \times 0.5 = 0.75 \end{aligned} $$
用户B、C相比,我们更愿意推荐C给A作为好友。尽管B的活跃程度非常高,但是与C与A的在线习惯更为匹配。这种推荐方案符合我的要求。
聚类+随机+排序
对于每一条推荐请求,计算其与所有用户的在线相似度,并排序推荐显然开销巨大。常见的推荐系统往往采用分层的架构减少计算开销,大致意思就是底层过滤一些根本不靠谱的,上层再对少量数据精排。
我们底层使用离线聚类,将所有用户打上类标签。在应对用户的推荐请求时,只对同一类的用户随机挑选若干,然后进行相似度计算和排序,并最终按序推荐给用户。通过控制聚类的类数,和随机挑选的用户数,可以保证最后的排序人数可控。
实验
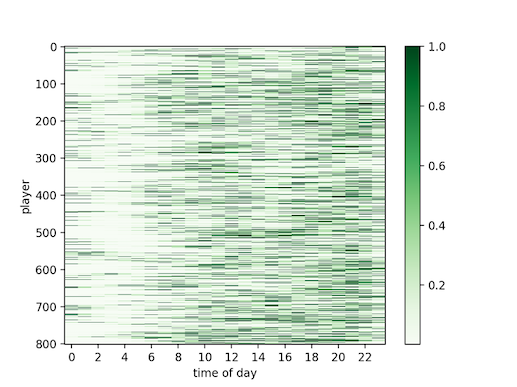
为了验证效果,我拿了某游戏800名用户一段时间的在线记录做验证demo。下图展示了这些玩家的在线向量。
下图中,我随机挑选了2个用户,计算所有用户和他们的在线相似度并排序。从效果来看,推荐效果还是比较理想的。
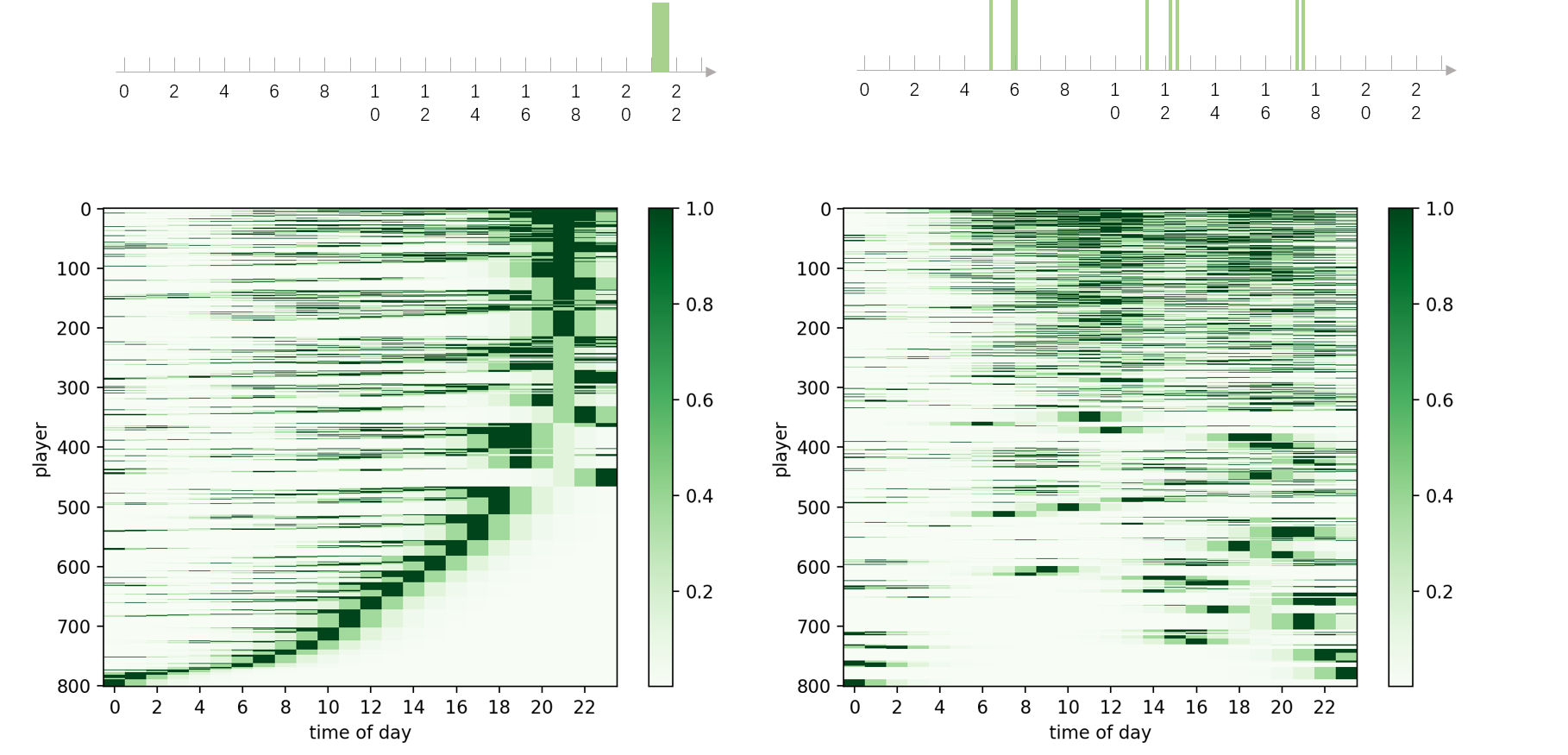
此外,我也试验了一下聚类的效果。从下图的实验结果来看,在聚为五类时,用户的在线习惯也比较明显的展现了。
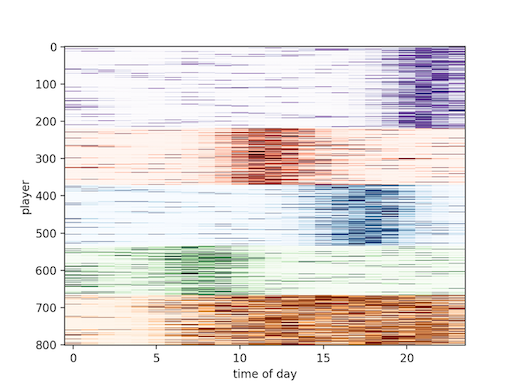
除了用于粗排,聚类也从一个侧面做了一些用户画像的工作。图6很好的展示了这点,从上到下的5类用户,分别对应晚间上线、中午上线、傍晚上线、上午上线、全天在线几种类型,利用这点可以采取更加精细化的运营策略。